

In the ever-evolving landscape of digital marketing, Search Engine Optimization (SEO) remains a cornerstone of online success. Among the myriad of tools at your disposal, the humble robots.txt file in WordPress often goes unnoticed. This small but mighty file serves as a gatekeeper, guiding search engine crawlers through your website and significantly influencing your SEO strategy.
In this listicle, “,” we’ll dive deep into the world of robots.txt, unveiling ten crucial insights that will empower you to harness its potential effectively. From understanding its structure and functionality to optimizing it for your specific needs, these tips will equip you with the knowledge to elevate your website’s visibility and control crawling preferences. Whether you’re a seasoned webmaster or just starting your online journey, expect to discover practical advice that can lead to tangible improvements in your search engine rankings. So, let’s turn the page on confusion and unlock the door to SEO success with these ten essential tips!
1) Understand the Importance of Robots.txt for SEO

- Definition and Purpose: A
robots.txtfile is a simple text file placed on your server that tells search engine crawlers which pages or sections of your site should not be accessed. This file plays a crucial role in managing your site’s indexing and ensuring only the desired content is shown in search engine results. By setting rules within this file, you can protect sensitive information and prevent duplicate content from affecting your rankings. - Impact on Crawl Budget: Each site has a limited crawl budget, the number of pages a search engine bot will crawl during a visit. If your robots.txt file is well-optimized, you can direct crawlers to valuable pages, ensuring they are indexed efficiently. Neglecting to properly configure this file may lead to important pages being overlooked, ultimately hindering your
SEOefforts. - Preventing Indexing of Low-Value Pages: Many WordPress sites come with autogenerated pages that offer little SEO value. By utilizing a
robots.txtfile, you can block these pages, such as your login or admin pages, from being indexed. This not only keeps your rankings strong but also improves your site’s overall performance.
Common Misconceptions
- Blocking Equals Security: It’s important to note that while
robots.txtcan prevent search engines from accessing certain content, it does not secure that content. This file is a guideline for crawlers, not a barrier. Sensitive data should always be protected through proper server-side security measures. - Not All Bots Follow Rules: While most major search engines honor
robots.txt, not all bots are created equal. Some may ignore the rules set forth within this file. Therefore, it is critical to take additional measures to safeguard your sensitive information.
Example of a Robots.txt File
| Directive | Description |
|---|---|
| User-agent: * | Applies rules to all bots |
| Disallow: /wp-admin/ | Prevents indexing of the admin area |
| Sitemap: http://example.com/sitemap.xml | Links to the site’s sitemap |
Monitoring and Testing Your Robots.txt
To ensure your robots.txt file is functioning as intended, regularly monitor and test it using tools like Google Search Console. Invalid entries could lead to significant loss in visibility. Consider implementing the following strategies for effective management:
- Regular audits of your
robots.txtfile to identify any outdated commands. - Utilizing testing tools available in Google Search Console to check if search engines can access your critical pages.
- Keeping abreast of changes in indexing and crawling standards as defined by popular search engines.
2) How to Create a Robots.txt File in WordPress
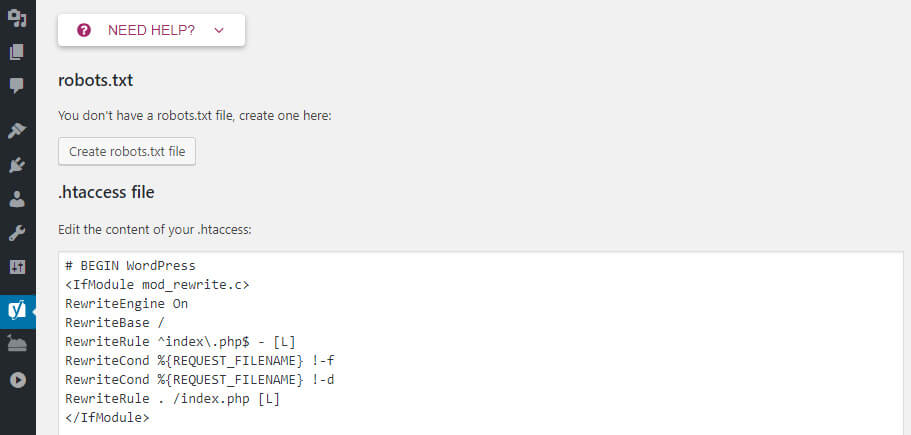
Understanding the Essentials of a Robots.txt File
Creating a Robots.txt file in WordPress is a fundamental step for controlling how search engines crawl and index your website. This simple text file holds significant power, allowing you to guide bots to the content you want them to access while restricting access to areas that are not beneficial for indexing.
Steps to Create Your Robots.txt File
Follow these steps to implement an effective Robots.txt file in WordPress:
- Access Your Site’s Files: Use an FTP client or your hosting provider’s file manager to navigate to your WordPress root directory.
- Create a New File: If a
robots.txtfile doesn’t exist, easily create a new text file namedrobots.txt. - Edit the File: Open the file in a text editor to specify your directives.
What to Include in Your Robots.txt File
A well-structured Robots.txt file requires clear and concise directives. Here are some commonly used commands:
| Directive | Description |
|---|---|
| User-agent: | Specifies which search engine crawler the directives that follow apply to. |
| Disallow: | Indicates which sections of the site should not be crawled. |
| Allow: | Permits crawling of specific sections within a disallowed directory. |
| Sitemap: | Provides a direct link to your XML sitemap for better indexing. |
Sample Robots.txt Configuration
Here is an example of a Robots.txt file layout that you can customize based on your site needs:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Allow: /wp-admin/admin-ajax.php
Sitemap: http://www.yoursite.com/sitemap.xml
This configuration prevents all crawlers from accessing the admin and includes directories, while allowing AJAX requests, ensuring essential functionalities remain intact.
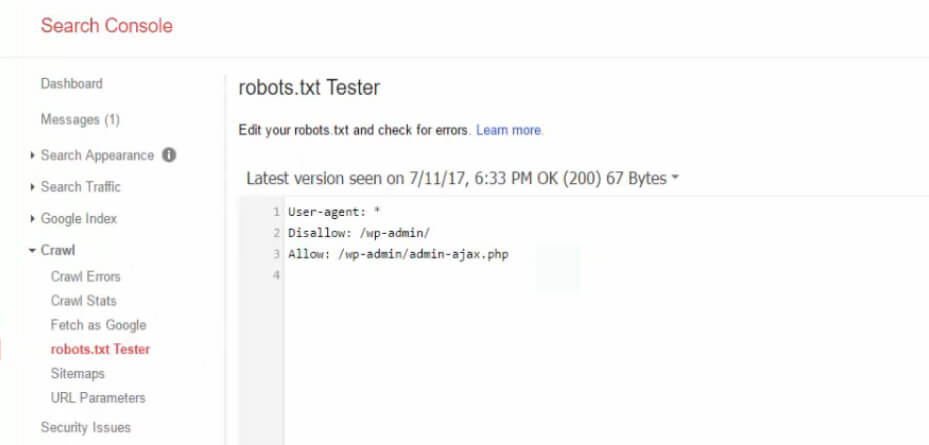
Testing Your Robots.txt File
After creating your Robots.txt file in WordPress, it’s crucial to test its functionality. You can utilize Google Search Console’s Robots.txt Tester tool, which allows you to check for errors and ensure that your directives are properly set.
Best Practices for Robots.txt Optimization
When drafting your Robots.txt file, consider the following best practices:
- Keep it simple and straightforward to avoid confusion for both crawlers and site managers.
- Avoid using a
robots.txtfile to block sensitive information; instead, use proper security measures. - Regularly review and update the file as your website evolves.
By following these steps, you can effectively create a tailored Robots.txt file in WordPress that closely aligns with your SEO strategy, helping search engines recognize and prioritize your valuable content.
3) Best Practices for Disallowing Specific Pages
Understanding the Disallow Directive
To effectively control crawler access to specific pages on your WordPress site, it’s crucial to grasp how the `Disallow` directive works within the robots.txt file. This directive signals search engines to refrain from indexing certain content. However, understanding its syntax is just the beginning:
- Syntax Accuracy: Follow the specific format:
User-agent: *followed byDisallow: /page-you-want-to-block. Ensure that each path is precise to avoid blocking larger sections of your site inadvertently. - Order Matters: The order in which directives are listed can influence their interpretation. Always list more specific paths before general ones.
- Test Before You Deploy: Use tools like Google’s Robots Testing Tool before finalizing your robots.txt file to avoid unintentional errors that could affect your site’s SEO.
Identifying Pages to Disallow
Not every page on your WordPress site needs to be indexed. Prioritize which pages should be excluded by analyzing:
- Duplicate Content: Pages that duplicate the core content of your site can harm your SEO rankings. Identify these and disallow them.
- Admin and Login Pages: Protect sensitive areas of your site by disallowing access to the admin or login pages. This helps secure your site from unwanted crawler traffic.
- Thank You or Thank You Pages: After conversions, these pages typically don’t need indexing and clutter search results.
Using Advanced Techniques for Fine-Tuning
In addition to the basic directives, consider employing advanced techniques to achieve maximum flexibility in your robots.txt file. Here are some beneficial practices:
| Technique | Benefit |
|---|---|
| Wildcard Characters | Use * to represent any number of characters to disallow multiple related pages. |
| Disallow Specific File Types | Prevent search engines from indexing files such as PDFs or images by specifying their file extensions. |
Monitoring and Revising the robots.txt File
Your robots.txt file is not static; it should evolve with your website. Regularly revisit and revise your settings based on:
- SEO Performance Analytics: Pay attention to how search engine crawlers are interacting with your site using tools like Google Search Console.
- User Feedback: If users are reporting issues finding content, consider whether the disallowed pages may be affecting their experience.
- Site Updates and Changes: As your site grows or changes, again reassess what should or shouldn’t be indexed.
4) Allowing Search Engines to Index Your Content

Understanding the Importance of Indexing
When it comes to enhancing your SEO strategy on WordPress, one of the most crucial steps is ensuring that search engines can index your content. Indexing is the process by which search engines like Google scan your web pages and add them to their databases, enabling them to present your content in search results. If your content is not indexed, you might as well be invisible online.
How Does Indexing Work?
Search engines use bots, or spiders, to discover and crawl your web pages. These bots follow links throughout the internet to find new content and assess its relevance based on various factors, including keywords, backlinks, and user engagement. To facilitate this, your robot.txt file in WordPress should be properly configured to allow indexing of the relevant pages while blocking those you want to keep private, like staging sites or certain posts.
Key Elements to Allow Indexing
- Ensure Proper Robot.txt Configuration: Make certain your robot.txt file permits indexing of your essential pages. Use the “Allow” directive for sections of your site you want indexed.
- Submit a Sitemap: Use plugins to create and submit an XML sitemap to search engines. This helps them easily locate and index your content.
- Utilize Meta Tags: Implement appropriate meta tags in your HTML to provide search engines with insights into your content. This can guide them on the relevance and context of your pages.
- Check for the ‘noindex’ Tag: Ensure that you aren’t inadvertently using the ‘noindex’ tag on pages you want indexed. This can be checked through WordPress SEO plugins.
Common Mistakes to Avoid
Even seasoned WordPress users can make errors that prevent successful indexing. Here are a few pitfalls to avoid:
| Mistake | Impact |
|---|---|
| Blocking critical directories | Your main content might not be indexed. |
| Not updating robot.txt after changes | Outdated settings can restrict access to new content. |
| Neglecting to check indexing status | You might miss out on valuable organic traffic. |
Best Practices for Effective Indexing
To maximize your chances of being indexed effectively, consistently apply best practices. These include:
- Regularly review robot.txt settings: Daily monitoring ensures you’re aware of what’s being indexed.
- Leverage SEO plugins: Tools like Yoast SEO can automatically help manage indexing issues.
- Promote internal linking: This enhances the ability of bots to crawl your site efficiently.
- Monitor search console insights: Use Google Search Console to identify indexing errors and rectify them promptly.
5) Using Robots.txt for Effective URL Parameters Management
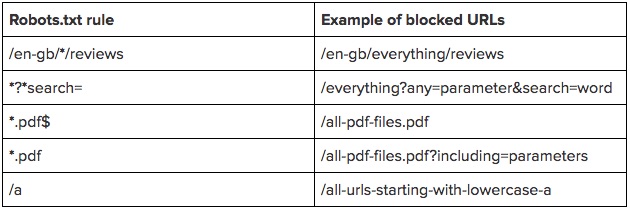
Understanding URL Parameters
URL parameters can significantly affect the way your website content is indexed by search engines. They are typically used for tracking sessions, filtering results, sort orders, and paging. However, excessive or poorly managed parameters can lead to duplicate content issues and dilute your site’s authority. This is where the robots.txt file comes into play, serving as a crucial tool in managing how these parameters interact with search engines.
How Robots.txt Helps
By utilizing the robots.txt file to manage URL parameters, you can guide search engine crawlers on how to interact with these URLs. Specifically, you can instruct crawlers to avoid indexing certain parameters that might create duplicates or clutter your search results. This can enhance your overall SEO strategy as it helps consolidate page authority towards your primary content.
Example of Effective Robots.txt Usage
Here’s how you can structure your robots.txt to handle URL parameters effectively:
User-agent:
Disallow: /?sort=
Disallow: /?session=
Disallow: /?filter=
Allow: /
In this example, we are telling crawlers to disallow any URLs containing the sort, session, or filter parameters, while still allowing crawlers to access the rest of your site. This ensures that only the primary page versions are indexed, supporting better ranking and keyword placement.
Analyzing Impact on SEO
Managing URL parameters with a well-defined robots.txt can minimize duplicate content risks, making it clearer for search engines what your primary pages are. Implementing this strategy correctly can lead to:
- Improved Crawl Efficiency: Reducing the number of URLs crawled saves crawl budget.
- Increased Indexing Priority: Ensures important pages remain the focus of search engines.
- Enhanced User Experience: Streamlining content reduces confusion for your audience.
Tools to Monitor and Adjust
Employing SEO tools can help you keep track of how effectively your robots.txt is managing URL parameters. Consider using tools that offer URL inspection and SEO audits to ensure your configuration is optimal. Here’s a quick comparison of popular tools for monitoring:
| Tool | Features | Price Range |
|---|---|---|
| Google Search Console | Crawl errors, URL inspection | Free |
| SEMrush | Site audit, page performance | $119.95/month |
| Ahrefs | Site audit, backlink analysis | $99/month |
Ultimately, effective management of URL parameters using robots.txt is essential for SEO success in WordPress. The right configuration not only ensures clear communication with search engines but also enhances user experience, helping your site to thrive amidst the competition.
6) Testing Your Robots.txt File for Errors

Understanding the Importance of Testing Your Robots.txt File
When optimizing your website’s SEO, ensuring your robots.txt file is without errors is crucial. This file plays a pivotal role in guiding search engine crawlers on how to interact with your site. Testing it can help prevent miscommunication between your site and search engines, ensuring that important pages are indexed while undesirable ones are excluded.
Common Errors Found in Robots.txt
As you embark on the journey of troubleshooting your robots.txt file, be aware of some typical issues that may arise:
- Syntax Errors: A missing user-agent declaration or improper formatting can lead to significant indexing problems.
- Disallow/Allow Misconfigurations: Incorrect rules can inadvertently block crawlers from accessing vital sections of your site.
- Unintentional Allowances: Allowing access to sensitive directories can expose your site to potential threats or unwanted indexing.
Tools for Testing Your Robots.txt File
Utilizing tools can significantly simplify the process of validating your robots.txt file. Here are some popular options:
| Tool Name | Description |
|---|---|
| Google Search Console | A direct way to test how Googlebot reads your robots.txt file. |
| Robots.txt Checker | Online validators that check for syntax errors and proper directives. |
| SEMrush | Provides advanced strategies for troubleshooting and optimizing your robots.txt. |
Steps to Test Your Robots.txt File
Follow these simple steps to ensure your robots.txt in WordPress is functioning correctly:
- Access your site’s robots.txt file by navigating to
yoursite.com/robots.txt. - Copy and paste the content into a testing tool to check for syntax errors.
- Simulate the crawl using tools like Google Search Console to see if the right pages are being disallowed.
- Make adjustments based on the feedback from your testing tool and revalidate.
Regular Maintenance of Your Robots.txt File
Like any other element of your site, your robots.txt file requires ongoing assessment. Regularly revisiting this file helps ensure that it aligns with your current SEO strategy, as your website evolves over time. Automated tools can notify you of any issues that arise, but periodic manual checks will provide an additional layer of confidence in your site’s SEO health.
Making the effort to thoroughly test your robots.txt file ensures that you maintain full control over which parts of your site search engines can access. By addressing errors and keeping your directives clear, you’re not just improving your SEO; you’re also enhancing your site’s overall user experience.
7) Common Mistakes to Avoid in Robots.txt

Understanding the Pitfalls
When configuring your robots.txt file in WordPress, it’s crucial to navigate the common mistakes that could undermine your SEO efforts. Failing to understand how this essential file works can lead to significant indexing issues and visibility problems for your site.
Ignoring the Default Settings
Many WordPress users overlook the importance of the default settings in their robots.txt file. While the CMS generates a basic file that is suitable for many sites, moving forward without reviewing these settings can be detrimental. Always ensure that the settings align with your SEO strategy. For example, if your default settings block important directories or files, such as your XML sitemap, search engines may not effectively crawl your site, hindering your organic traffic.
Incorrect Syntax
Another common pitfall lies in the syntax used within the robots.txt file. Users often make errors in the formatting, which can lead to unintended consequences. Here are typical mistakes to avoid:
- Misplaced directives: Always place user-agent and disallow directives correctly; improper positioning can mislead search engine bots.
- Wrong file size: Keep your robots.txt file concise. Lengthy files exceeding the typical size limit can lead to crawl issues.
Preventing Access to Important Pages
While blocking irrelevant sections of your website is essential, it’s equally critical to ensure that valuable pages are accessible to search engines. Common mistakes include inadvertently disallowing pages with high SEO potential—this can prevent indexed pages from ranking well. For instance, blocking your blog section or product pages could drastically impact your visibility.
Overusing Disallow
In an effort to safeguard content, many users resort to extensive disallow rules. However, overusing this directive can create roadblocks for search engines attempting to crawl your site. Instead, allow search engines to index as much content as possible while being selective about what to restrict. This strategy enhances visibility while maintaining control over sensitive content.
Neglecting to Update Your Robots.txt
Lastly, forgetfulness can lead to outdated directives in your robots.txt file. As your WordPress site evolves, so too should your robots.txt file. Neglecting to update it can hinder new content from being indexed. Schedule regular reviews and adjustments to ensure that your file reflects the current structure and strategy of your website.
Summary of Common Mistakes
| Error Type | Impact | Solution |
|---|---|---|
| Ignoring Default Settings | Potentially blocks important content | Review and adjust settings |
| Incorrect Syntax | Can mislead search engines | Double-check formatting and directives |
| Blocking Important Pages | Reduces page visibility | Evaluate which pages to allow |
| Overusing Disallow | Creates crawl barriers | Be selective with directives |
| Neglecting Updates | Old files may hinder new content | Regularly review and revise |
8) How Changes in Robots.txt Affect Crawling and Indexing

Understanding the Impact of Robots.txt Modifications
When you modify your robots.txt file, you’re essentially communicating with search engine crawlers about what content should be prioritized or completely ignored. This subtle interaction can significantly alter how your site’s pages are crawled and indexed in search engines. A single line change can either enhance your site’s SEO visibility or restrict its potential reach.
The Key Directives
The robots.txt file utilizes various directives to manage crawler permissions. Here are some essential ones you should be aware of:
- User-agent: Specifies which search engine bots the rule applies to.
- Disallow: Instructs crawlers not to access a certain path or page.
- Allow: Lets crawlers index a specific page or directory, despite the broader restrictions of the Disallow command.
- Sitemap: Points bots to your XML sitemap to streamline crawling.
Each of these directives plays a crucial role in defining the boundaries of your site’s SEO strategy, directly affecting how changes in the robots.txt might impact crawling efficiency and indexing propensity.
Common Scenarios of Misconfiguration
Misusing the robots.txt file can lead to significant SEO pitfalls. For instance, implementing a blanket “Disallow: /” directive will completely block all crawlers from indexing any content on your site. Conversely, unnecessary restrictions on crucial pages can lead to missed opportunities in organic search traffic. Below are a few common mistakes:
| Error Type | Potential Impact |
|---|---|
| Entire Site Disallow | No pages indexed; your site becomes invisible to search engines. |
| Excessive Allow Rules | Crawlers waste time on irrelevant content; key pages get overlooked. |
| Inconsistent File Management | Different files yield conflicting directives, confusing crawlers. |
Best Practices for Effective Crawling and Indexing
To harness the full potential of your robots.txt file while optimizing for search engines, consider the following expert tips:
- Audit Regularly: Periodically check your robots.txt file to ensure it aligns with your current SEO strategy and site structure.
- Test Changes: Utilize tools like Google Search Console to test how changes affect crawlability and indexing.
- Be Specific: Use precise paths in your Disallow and Allow directives to avoid unintended exclusions.
- Keep it Simple: A clear and concise robots.txt file enhances efficiency for crawlers.
By adopting these practices in managing your robots.txt in WordPress, you can facilitate better crawling behavior and ensure that your most valuable pages are indexed, thereby promoting better rankings and increased organic traffic.
9) Understanding Crawl Delay and Its Impact

Crawl delay refers to the amount of time that a robot or web crawler should wait between successive requests when accessing a website. This setting can significantly influence how efficiently search engines like Google index your content. In the context of robots.txt in WordPress, understanding crawl delay is crucial for optimizing both site performance and SEO strategy.
The Importance of Crawl Delay
When you specify a crawl delay in your robots.txt file, you are essentially instructing search engine bots to limit the frequency of their visits. This can be particularly beneficial for:
- Server Load Management: Implementing a crawl delay helps prevent overwhelming your server, especially during peak times.
- Better Resource Allocation: By reducing the number of simultaneous requests, you can ensure that your site’s resources are allocated more effectively to users rather than bots.
- Improved User Experience: A stable server response time leads to quicker load times for your visitors, enhancing their browsing experience.
How to Set Crawl Delay in Your robots.txt
To set a crawl delay, you can easily edit your robots.txt file within your WordPress installation. Here’s a simple example:
User-agent: *
Crawl-delay: 10This directive tells all web crawlers to wait 10 seconds before making another request. Keep in mind that not all bots observe crawl delay rules, but major players like Google and Bing typically do.
Evaluating the Impact of Crawl Delay
Setting an appropriate crawl delay can lead to more efficient indexing, but it can also have unintended consequences if not calculated correctly. Here are some factors to consider:
- Indexing Speed: A longer crawl delay can slow down how quickly new content gets indexed, which might delay search engine visibility.
- Content Updates: If your site frequently updates content, a short crawl delay may benefit timely indexing.
- Bot Behavior: Different crawlers may interpret delay settings differently, leading to variance in indexing behavior.
Measuring the Effects
To assess the real-world impact of your crawl delay adjustments, utilize tools such as Google Search Console to monitor changes in crawling and indexing rates after modifications are made. Track metrics such as:
| Metric | Pre-Adjustment | Post-Adjustment |
|---|---|---|
| Crawl Rate | 200 requests/day | 150 requests/day |
| Indexing Speed | 3 days | 5 days |
| Server Response Time | 1.5 sec | 1.0 sec |
Adjusting crawl delay settings in your robots.txt in WordPress is more than just a tactical maneuver; it’s a balancing act that considers the needs of search engine crawlers alongside user experience and server health. By fine-tuning this setting, you can help to streamline the indexing process while maintaining the integrity of your website’s performance.
10) Regularly Updating Your Robots.txt for SEO Strategy
Importance of Regular Updates
Having an up-to-date robots.txt file is crucial for a successful SEO strategy. Over time, your website structure, content, and even your SEO goals may change. This means that the sections you want to block from indexing or the directories you want to allow can also shift. Regular updates ensure that search engines precisely understand which parts of your site are valuable and which should remain private.
Key Considerations for Updates
When you update your robots.txt, consider the following factors:
- Content Changes: If you’ve added new sections, such as a blog or product pages, make sure these are indexed if relevant.
- SEO Audits: Regularly conduct audits to identify URLs that may need to be restricted for better optimization.
- User Experience: Ensure that critical resources, like images and scripts, are still accessible to bots, as this can significantly impact how your site performs in search rankings.
Tracking and Monitoring
Monitoring your robots.txt changes is vital for maintaining effectiveness. Utilize tools like Google Search Console to check how search engines interact with your updated file. Pay attention to:
- Indexing Issues: Keep track of any crawl errors that arise after making changes.
- Search Traffic Patterns: Analyze whether your traffic increases or decreases in relation to updates.
- 404 Errors: Limit potential usability issues by ensuring important pages aren’t inadvertently blocked.
Example of a Properly Structured Robots.txt
Here’s a simple visualization of an effective robots.txt configuration:
| User-Agent | Disallow | Allow |
|---|---|---|
| * | /private/ | /public/ |
| Googlebot | /old-content/ | /blog/ |
| Bingbot | /temp-files/ | /images/ |
This table illustrates how to configure your robots.txt effectively, ensuring optimal results for both users and search engines.
Conclusion
To reap the full benefits of your robots.txt in WordPress, staying proactive about updates is essential. Your site will flourish in search rankings when you align your file with the current status of your website. Revisit your robots.txt at regular intervals, especially after any significant changes or updates to your content or structure. This personalized approach will drive organic traffic and elevate your overall SEO strategy.
Q1: What is a robots.txt file and why is it important for SEO?
A robots.txt file is a text file created on your website to instruct search engine crawlers on which pages to crawl and which pages to avoid. It is crucial for SEO because it helps control how search engines index your site, ensuring that only valuable content is submitted to search results. Properly configured, it can prevent duplicate content issues and enhance the overall efficiency of your SEO strategy. For more detailed insights, check out Wikipedia.
Q2: How do I access and edit the robots.txt file in WordPress?
You can access your robots.txt file by using a plugin or FTP. To use a plugin like Yoast SEO or All in One SEO, simply install it and find the File Editor in the settings. If you prefer FTP, navigate to the root directory of your WordPress installation and find or create the robots.txt file there.
Q3: What common directives should I include in my robots.txt file?
Some key directives to consider include:
- User-agent: Specifies which search engine crawler the rules apply to.
- Disallow: Tells crawlers which paths or pages should not be indexed.
- Allow: Overrides disallow directives for specific pages within a disallowed directory.
- Sitemap: Provides the location of your sitemap to help search engines find it easily.
Q4: Can I block search engines from indexing certain pages?
Yes, you can block specific pages or entire directories by using the Disallow directive in your robots.txt file. For example, if you want to block a directory named private, you would add:
Disallow: /private/Q5: What should I avoid including in my robots.txt file?
Avoid including sensitive information or private data in your robots.txt file, as it is publicly accessible. Additionally, be cautious about accidentally blocking your entire site by improperly using the Disallow: directive without exceptions.
Q6: How often should I update my robots.txt file?
You should update your robots.txt file whenever you make significant changes to your site structure or content strategy. Regular reviews are beneficial, especially if new sections of your site are created or old ones are removed.
Q7: Can I test my robots.txt file for errors?
Yes, you can use tools like the Google Robots Testing Tool to ensure your robots.txt file is correctly configured and no important content is inadvertently blocked from search engines. This is crucial for maintaining active indexing and optimizing your SEO.
Q8: Does a robots.txt file guarantee that pages will be ignored by search engines?
No, while a robots.txt file suggests to search engines which pages to ignore, it is not an absolute guarantee. Search engines may still choose to index these pages based on other factors. To ensure more stringent control, consider using noindex meta tags within your HTML for individual pages.
Q9: How can a well-structured robots.txt file improve site performance?
A clear and concise robots.txt file can enhance site performance by reducing the crawl load on your server, allowing search engines to focus on indexing the most important parts of your site. This can lead to better indexing rates and potentially improved rankings.
Q10: Where can I find more resources to learn about robots.txt and SEO?
For in-depth information on robots.txt files, SEO best practices, and various directives, check out:
As we wrap up our exploration of “,” it’s clear that understanding the ins and outs of your robot.txt file is crucial for optimizing your website’s performance in search engines. Automating your SEO strategy is more than a trend; it’s a necessity in today’s digital landscape. By implementing these handy tips, you can enhance your website’s visibility while directing search engine crawlers precisely where they need to go.
Remember, a well-structured robot.txt file can serve as your site’s first impression on search engines, guiding them through your content without any confusion. With the right approach, you’ll not only improve your site’s indexation but also skyrocket your chances of ranking higher on search results.
For those eager to dive deeper into this topic and further improve your SEO strategies, we recommend checking out resources like Yoast’s Guide to Robots.txt for more detailed insights. Keep experimenting, keep learning, and watch your WordPress site flourish in the competitive online arena. Happy optimizing!

{kind=link}